linux进程内存占用分析
线上服务一般都会遇到因为代码bug或者逻辑不合理导致内存占用暴涨的情况(例如内存泄露),也有可能在线上环境发现内存占用太高和预估不符的情况。单纯分析代码人肉查问题不总是靠谱,此时最直观的方式就是profile进程的内存占用问题。如果遇到了c/c++开发的服务,或者需要分析类似java堆外内存泄露的问题,gperf(tcmalloc)是一个比较好的选择。
进程内存模型分析
内存占用首先需要定位的就是内存占用不合理的地方在哪?一般情况下都发生在堆内存(毕竟栈内存空间太有限了,没啥可以发挥的地方)。也可能是使用了海量的共享内存,但是这部分一般都是可控的。
查看内存占用一般用top就能直观地看到一部分信息,top -p <pid>查看对应进程内存占用,一般长这样:

这是我的测试服务器上的一个nginx的截图。
有关于进程的内存的条目有五项
VIRT虚拟内存RES实际物理内存占用SHR共享内存CODE是代码段占用的内存DATA是指堆、栈上申请的总空间
RES代表了实际上占用的物理内存,内存占用过高也往往是讨论的这一块,这块包括了堆,栈,使用的共享内存等。man top里说到RES=CODE+DATA,这在大部分情况下说的都是不正确的,很显然从上图中我们就能看出了。
SHR RES和VIRT的关系
以下是一段申请共享内存的样例代码:
1 | |
以下分别是执行这段代码之后的几个时间点的内存占用信息:




参考文中注释的内容,我们可以总结出几点内容:
shmget申请贡献内存连virt部分都不会新增。应该只是在内核空间中新建了一个共享内存的信息。shmmat会给virt增加16M的占用。但是此时RES和SHR都没有任何增长。memset真正用到了共享内存申请的空间,此时可以看到RES和SHR都增加了大概4M的空间。
这里很显然我们会得到一个结论:申请的共享内存无论是否使用,都会增加VIRT的占用(毕竟是增加了虚拟内存空间),但是只有实际上内存页被访问到之后,才会真正地增加内存使用(应该是发生了缺页中断之后,才会真正地有一个映射)。
因此我们要有一个清晰的认知,内存占用的大小主要关注RES,只要RES维持在一个合理的范围内,实际上是很难发生OOM的。但是同时VIRT也并非不需要关注,如果VIRT超过RES很多,可能就代表在某个特殊的时刻内存使用会暴涨了。主要的原因来自于申请却未使用到的共享内存。
进程内存细节查看
类似的信息也可以在/proc/<pid>/status里查看到,例如我服务器上的nginx:
1 | |
其中VmSize对应VIRT,VmRSS对应RSS。其余的信息都可以google到,不再赘述。
但是这里只输出了全局的修改,我们日常定位内存占用异常的时候会想要知道进程的堆占用,共享内存占用(比如python的内存管理就会直接用mmap申请大段内存)等等。此时可以查看/proc/<pid>/smaps的数据,它是基于/proc/<pid>/maps的扩展,展现了更加详细的信息。
每一段VMA(虚拟内存区域,即vm_area_struct 指向的区域)都在smaps里分别列出。以下是我的某个在线服务的堆内存段VMA:
1 | |
其中第一行的基础信息对应情况如下:
2fd84000-e9f5a000虚拟内存的开始-结束地址。rw-p内存段的权限。rw就是一般权限标识了,最后的p代表私有(s代表共享)。00000000该虚拟内存段起始地址在对应的映射文件中以页为单位的偏移量。因为堆内存是直接申请的内存页,不对应一个文件,所以是0或者vm_start/PAGE_SIZE。00:00文件的主设备号和次设备号。对匿名映射来说,始终为00:000被映射到虚拟内存的文件索引节点号,对于匿名映射始终是0
同样的一个进程下,我们还可以看到链接的libc++动态库的vma信息:
1 | |
请注意这里的Rss段,因为libc++这个动态库被许多进程共享,所以实际由本进程承担的只有100k。但是要注意的是这里无论是计算Rss还是Pss之和都和Res对不上。可能的原因也许来自于malloc内存申请的方式会留有缓存,以及内存对齐等原因。
至此通过对于这些信息的分析我们已经可以大致定位到内存占用的大头了:堆、共享内存,包括具体到是否是第三方库以及是哪个库。
使用tcmalloc分析堆内存
一般情况下我们认为内存出现问题的原因都会来自于自己的堆内存。 因为如果在代码中使用了共享内存,那么量肯定是可以预期的,入口也非常稳定。加一些日志一般都可以很简单地定位到问题。而第三方库测试比较充分,出问题概率也不高。诸如new和delete不匹配之类的花活一般都是出现在我们的业务代码中的。
使用tcmalloc可以比较方便地分析内存申请分配的情况。请注意不要使用太高的版本的gperf,否则在申请大块内存的时候会触发异常。我在自己的环境中测试出一个可行的组合是gperf2.2+libunwind1.6.2(64位机器需要)。
工程有两种方式引入tcmalloc,静态链接和使用LD_PRELOAD。静态链接方式需要在链接的时候加入参数-ltcmalloc(库目录需要包含libtcmalloc.a)。LD_PRELOAD则是在shell中类似如下定义:
1 | |
开启profile也有两种方式,侵入代码或者定义信号。使用信号很简单,只需要修改shell环境,如下所示:
1 | |
这样内存稳定之后发送信号触发dump profile文件:
1 | |
就会生成对应的profile文件了。
或者也可以在代码中显示地开启关闭和触发dump,如以下代码:
1 | |
编译:
1 | |
运行之后我们会得到4个文件:
1 | |
这是因为默认一次性分配超过100k内存之后就会dump一次。可以设置HEAP_PROFILE_INUSE_INTERVAL为0关掉它。其他的选项设置还有:
HEAP_PROFILE_ALLOCATION_INTERVAL: 内存每增长这一数值之后就dump 一次内存。默认1G。HEAP_PROFILE_TIME_INTERVAL: 每隔一段时间dump一次内存。默认为0即不开启。
分析得到的文件./test.log.0004.heap,使用如下命令转换成pdf(否则调用链复杂的程序看着有些麻烦):
1 | |
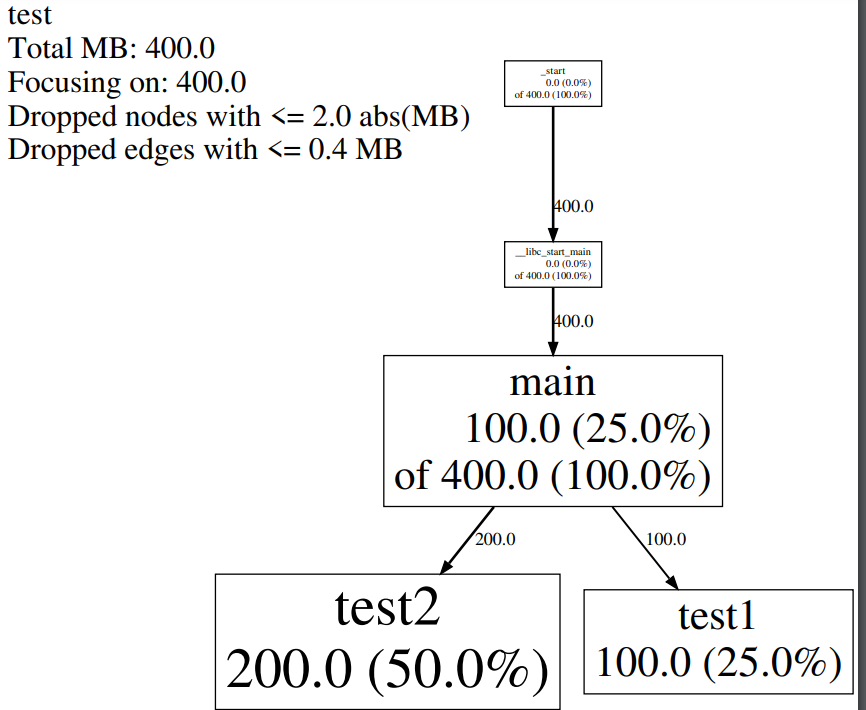
生成的pdf如图所示:可以知道test2申请了50%的内存,test1申请了25%,main的调用链上申请了100%,但是其中只有25%是main自己申请的。通过调用图我们就可以分析出在申请的过程中哪个函数申请了较多未释放的内存了。
结语
在本文中我们通过分析进程的内存空间,知道了如何定位内存占用的大头。并且针对堆内存使用tcmalloc来定位可能的热点。