protobuf的二进制编码结构
Protocol Buffers是一种跨平台的序列化数据结构协议,通过.proto文件作为DSL描述,并且将数据以二进制方式字节流方式编码。了解protobuf的编码方式,对于合理组织自己的协议,以及优化业务代码都比较有帮助。
value的编码
protobuf中的value类型类型大致可以分为这几种,我们称之为wire type,和protobuf的类型对应关系如下:
1 | |
如果不确定所用的数据类型对应的什么wire type也可以从导出的代码里看一下注释,以下代码是官方go protobuf导出的部分代码:
1 | |
接下来我们分开整理一下wire type的数值是如何保存的。
Varint
这里包括了uint32,uint64,in32等整数类型。需要编码varint时,会先将对应的整数转换成uint64,之后再存成varint。例如编码int32时,代码如下所示:
1 | |
因此我们可以将varint的编码看做是uint64的编码。对于8字节的varint,大部分情况下前边都是有很多0占据的,为了节省空间,varint的编码采用每个byte的第一位作为标识位,后7位作为数据位的方式。
例如对于123456这个整数,uint64的编码是00011110001001000000(忽略前边空的byte),varint编码方式如下:
这种编码中,每个byte最高位都叫做最高有效位,most significant bit即msb。如果最高有效位是1,那么代表后边的字节还属于这个varint的,否则就代表这是最后一个字节了。由此我们可以节约一些空间,例如对于123456就可以用3个字节编码,节省了5个字节。
同理在解码的情况下,就是依次读取字节,直到最高位为0为止,再将读到的字节按照小端序转换为对应的数字。
对于比较熟悉补码的读者会发现,这种方法在遇到负数的时候是很低效率的。例如-1转换成uint64是18446744073709551615,如果直接用varint存储就需要10个字节,十分低效。为此protobuf引入了zigzag编码。本质上zigzag也是非常简单的,转换方式如下:
1 | |
在zigzag编码下,编码会变成如下映射:
这样编码的长度和绝对值相关,规避了小负数补码的问题。
请注意,varint中,只有sint32和sint64是使用zigzag方式编码的。因此,如果在业务中使用非负数,可以使用uint32和uint64,否则需要使用sint32和sint64以减少编码长度。(很疑惑int32为什么有必要存在,或者说为什么int32 不直接使用zigzag)。
fixed32和fixed64
这两项就没有太多可说的,就是存储4位or8位的数字,主要用于存储float和double。对于某些特殊场合的整数,比如自定义ID算法计算得到的uint64的ID时,因为大概率可以确定ID一定是63~64位,使用varint大概率是要比8位要多了,我们可以选用Fixed64这样的定长类型。
唯一需要注意的是,对于float和double需要转换成IEEE 754的浮点数标准存储。一般情况下各语言的标准库都能处理好,只有在实现自己的protobuf库时需要额外注意。
Bytes
这个类型包含了message bytes repeated string,编码方式大同小异,都是长度+数据的组合。这里的长度统一都使用了varint来编码。
例如对于message的编码,会先编码整个message的长度。再递归地编码这个message。如下图所示:
对于字符串,额外的操作是校验字符串是否符合utf-8规范。
额外说明一下对于repeated,在protobuf2版本内可以指定是否为packed,例如:
1 | |
这种声明的方式在protobuf3中已经废弃了,所有的repeated都是按照packed的方式来压缩。两种压缩的区别如下: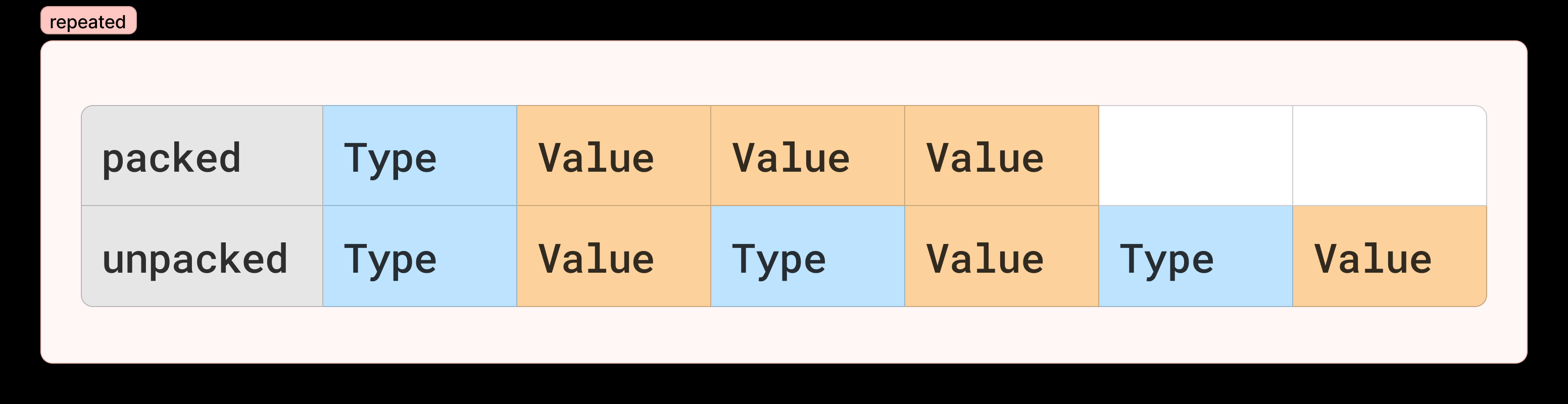
kv结构
不同于json,xml这类的自描述协议,protobuf本身附带的信息不足以完全还原protobuf结构体。拿到了一段字节流想要还原整个proto是不现实的(当然,也可以靠猜的)。但是给定一段字节流,我们至少可以从中还原出field的数量和大致类型。
如下是一段简单的proto文件,我们可以用protoc导出并且在go工程中引用它:
1 | |
根据这个proto生成一个结构体,并且dump序列化之后的字节流:
1 | |
这样我们就可以解析名为test.bin的字节流文件。首先先上结论,test.bin的数据分布如下图所示: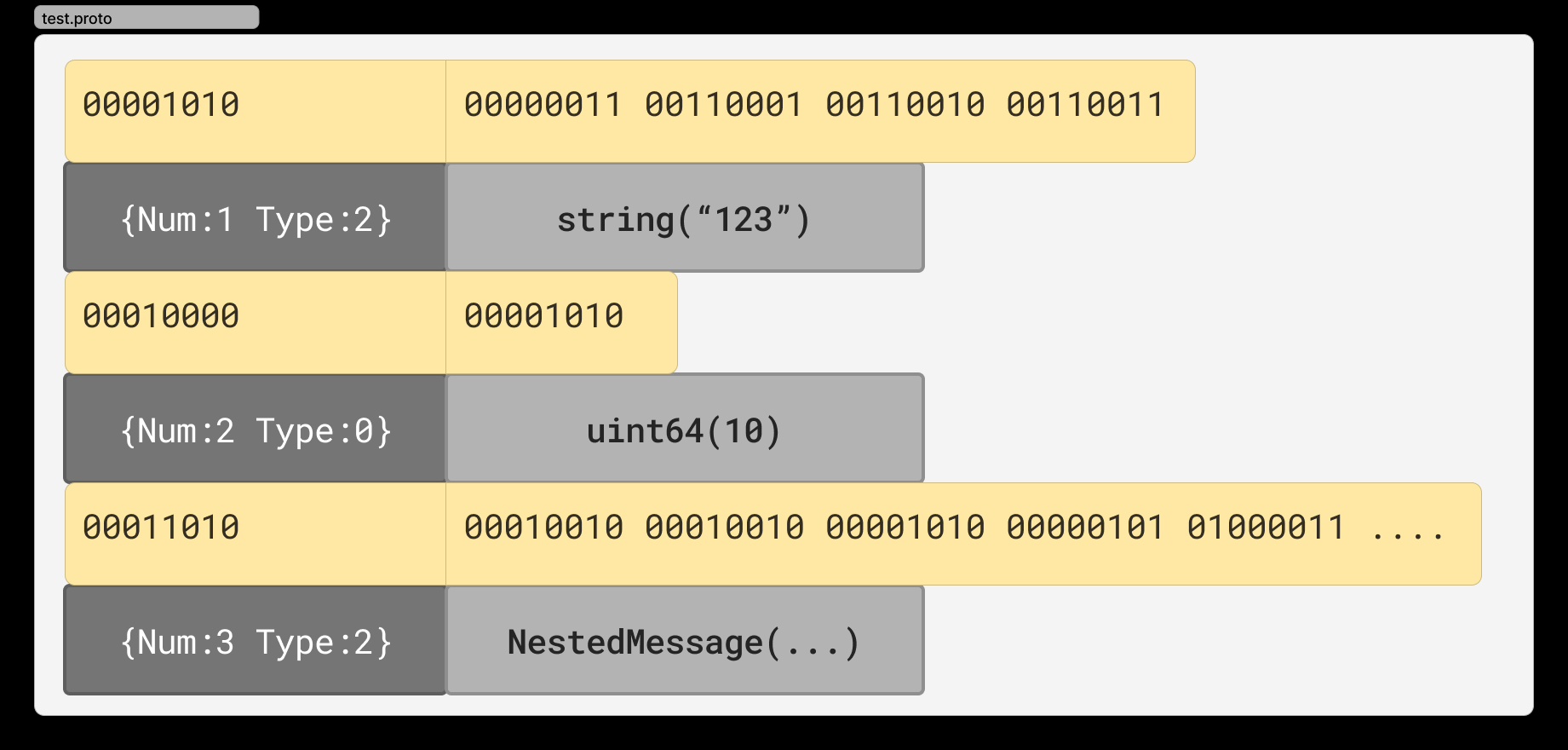
数据分为三段,编码后的字节流是以k-v形式组成了若干段数据,再将这些数据段简单拼接在一起得到的。其中v部分就是上一章节中描述的的数据,接下来我们先解释一下k的形式:
protobuf的field
在上一节中,我们可以从图中发现对应MyMessage中3个field。其中每个field都是以k-v的形式组合,例如string name = 1;占据了第0~4个byte,其中第一个byte用于描述field 。每个field的形式如下所示:
其中Num就是在proto里定义的序号,Type就是前文中提到的wire type,field和type一起被编码进了同一个byte中,field = Num<<3 | Type。
这里的field是用varint的形式存储的。因此在业务开发遇到field较多的消息时,建议谨慎规划0~15的field num,尽量将这一段留给经常需要设置的field。原因是只有0~15的数左移3位之后还能保持7个bit,这样才能在一个varint内编码完。
作为例子,对于以下声明
1 | |
这个field的varint编码就是(小端序 补齐msb),需要2个byte。
1 | |
事实上,虽然field是使用varint编码,但是它最大长度为32位。因此field num的最大序号为536,870,911(1<<(32-3) - 1)。
message编码
最后在编码了field和value之后,message编码就是简单地将k-v依次拼接得到。
事实上,protobuf不要求field number有序,也就是说k-v完全可以按照”3-2-1”这样拼接;同样地,也不要求tag是完全的,对于以下消息,就只会编码field1和field3:
1 | |
protobuf反序列化字节流时,也是依次读取每个field的kv组合并且填充到结构体中。
至此我们可以推断出一些结论:
首先,以下这两段代码生成的是一致的字节流。
1 | |
这样我们可以对于用到protobuf的地方做一些灵活的修改,例如业务中动态地给msg添加信息(一般用在网关,转发服务上)。
其次,注意到在编码的结果中field name,即Name,Age之类的信息是不编码进最终的字节流中的。因此可以随意给字段命名,不用考虑长度的影响(相对地json和msgpack就需要考虑到这一点)。此外两个结构体如果有部分字段的field是相同的(number和type),那么它们可以在某种程度互相兼容,只是会丢失无法对齐的部分信息。这也是protobuf前后向兼容性的来源。
总结
通过对protobuf的编码方式分析,我们可以得到一些指导我们业务开发的结论。
- 对于有符号整数,尽量使用
sint32和sint64,这样可以使用zigzag编码以避免补码对varint带来的影响。 - 如果已知某些
field是大整数,二进制编码占用7~8个byte,那么可以考虑使用fixed32或者fixed64以避免varint带来的额外开销。 - 规划
field number时优先将0~15的位置留给更经常被赋值的field,以减少整体的编码长度。 - 编解码用的
proto文件可以不一定完全相同,只要类型能对齐就能解码。 - 可以方便地给字节流增加一些
field,但是减少和替换就麻烦一点(最糟糕情况需要遍历完整个byte数组)。 - 在只有字节流文件的情况下,我们最多能判定目标
proto协议至少有多少个field,但是无法正确地解码。因为不同类型的value会编码成相同wire type,例如varint,没有proto文件的情况下我们无法确定是要解码成uint64还是int64。 - 前边这项也告诉我们
protobuf无法兼容前后版本同一个field type有变化的情况,如果需要变更field type建议新增加一个field。
进一步思考
我在研究protobuf的结构时,一直在思考:protobuf需要两边都有一个DSL文件才能正确编解码,原因就在于wire type的类型实在太少了,不能完全描述完数据结构。但是对于field number来说,(1<<(32-3) - 1)的最大限制应该是一个无论如何都达不到的地步。所以再多给wire type3位数据,让wire type最大值来到64个,就应该可以摆脱DSL了。
但是这样几乎板上钉钉需要2个byte来描述field,对于大部分只有小整数交换的message来说要增加1/3~25%的编码长度。想到这里我不得不对google的人说:
可以下载样例demo并且运行make编译工程。