Cap'n Proto的编码格式分析
Cap’n Proto是一个高性能的数据交换格式,而且还附带了一套性能优良的RPC框架实现。是Protobuf2的作者Kenton Varda于 2013 年 4 月开源发布的,开源10年之后也在23年发布了第一个稳定支持版本1.0。
Cap’n Proto号称编解码接近0开销,比protobuf快无数倍。当然我们想想也知道这是个不现实的事情,但是能这么说肯定是它在速度上有两把刷子,因此本文我们就来分析看看它的编码格式究竟是什么样的,以及实际使用上会有什么优缺点。
和Protobuf的区别
首先给定一个message的定义(上为cap’n proto,下为protobuf):
1 | |
我们在代码中给title设置字符串”War and Peace”,设置pageCount的值为1440。它们编码后的数据排布如下图所示: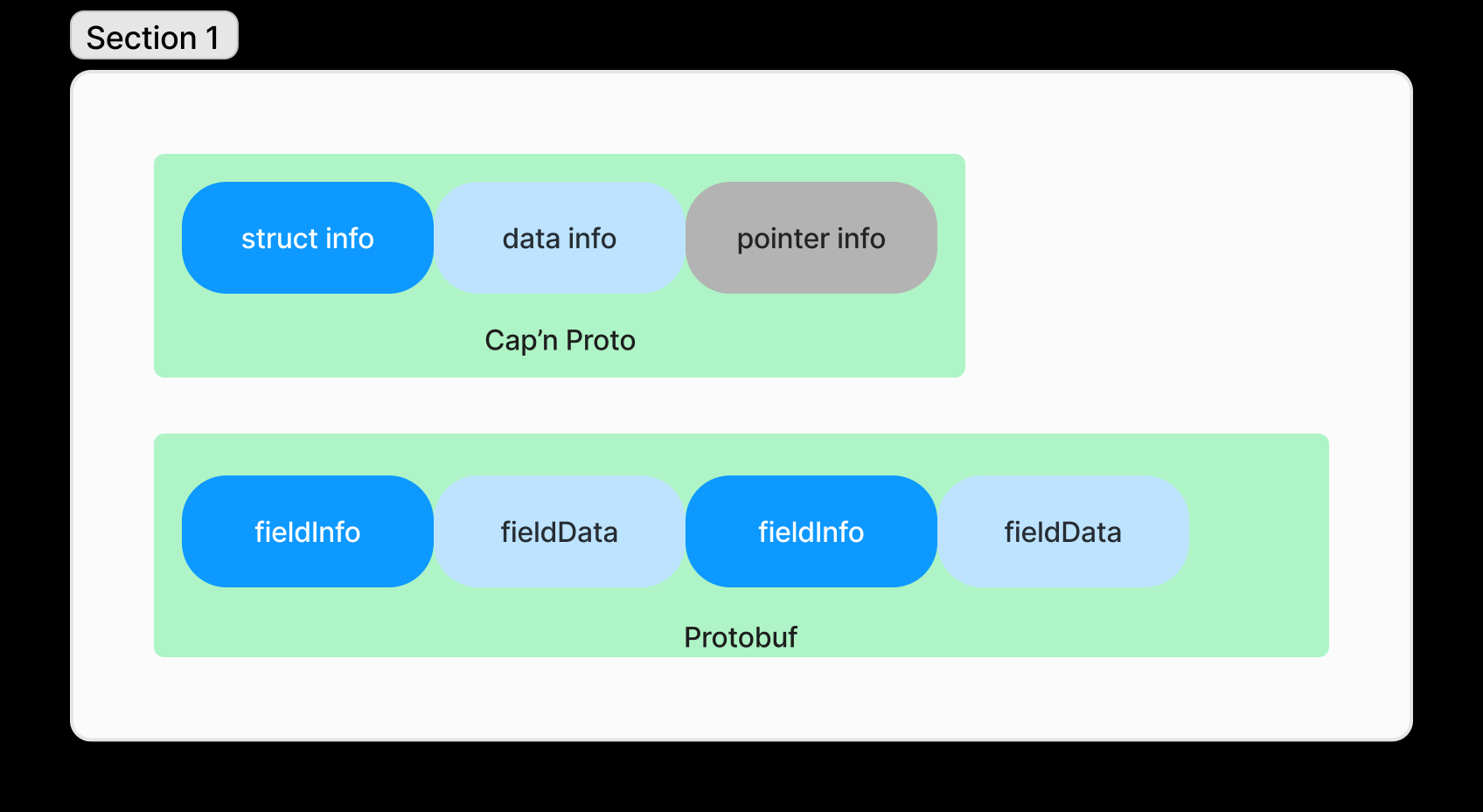
可以发现差别之处,对于一个message,在protobuf中,每个field-value都是独立编码的。而对于cap’n proto来说,每个message都需要事先将所有的字段都在struct info中声明,并且标明每个字段相对于结构体的偏移量。
这种差别导致了protobuf在读取的时候并不能很快地忽略一些字段,因为我们无法知道每个字段在这段字节流中的偏移量,因此你总是需要经历一个读取filed并且抛弃的过程。
相对来说protobuf会更有利于动态增加一些字段。考虑到在某些场景下你需要给rpc的参数统一加上一个id(例如发送方发送的Book有两个字段,而接收方的Book额外多一个id),对于protobuf只需要简单地在数据之后增加一对kv的编码即可。但是cap’n proto就比较困难,我们需要对于struct info整体做一个修改,这样几乎相当于要做一个完成的序列化-反序列化过程,同时再做一次数据拷贝的过程。
Cap’n Proto的编码结构
在cap’n proto中,数据以segment的形式组织。对于数据量不大的情况(一个message长度在2000以内)一般会以一个segment的形式组织。并且也允许将所有数据塞到一个segment里,因此之后我们聚焦单个segment的message。不同message主要影响字段直接的offset计算,整体结构大同小异。
此外,需要注意的是,capnproto中,为了内存对齐,会有一个最小的长度单位叫作wordSize,在我的机器上wordSize=8。这意味着只会分配wordSize整数倍长度的内存空间。因此在cap’n proto的内部会有一些内存浪费,但是(据官方所说)可以通过压缩算法找补回来。
segment头的编码
首先对于每个segment,最开始的一个word(长度为wordSize)里会标明这个segment里这个segment剩余的长度是多少,这个长度标识的是有多少个word。已知整个segment长度是40,因此是5个word(这个是后边计算出来填充的,这里先当作我们已经算好了)。因此最开始的8位是:
1 | |
capnproto的任何数字都以小端形式写入,这里不足一个word的高位补0,因此5的序列化就是0000 50000
pointer编码
首先,对于变长数据,例如struct,text这种,全都是以poiter+data的形式编码,pointer用来表示数据的定长信息,例如总长度之类。data用来描述变长信息,例如字符串的实际内容。
因此,对于Book这个结构体,我们首先需要写入它的pointer,再写入data(具体的数值)。struct pointer的信息也用一个word表示:
1 | |
- A:2 bits,固定是0,代表是struct pointer
- B:30 bits,偏移量,用于表示属于这个struct的数据距离本段信息结尾的距离是多少个word。在本例中紧接着就是属于
Book的数据,因此也是0。 - C:16 bits,data段的长度(多少个word)。这里data段指int这种定长的数据。
- D:16 bits,pointer段的长度(多少个word)。这里pointer指的是Text这种变长的数据。
在本例中,有1个定长,1个变长的数据, 不足1个word的要补足1个。因此struct pointer信息表示就是0 0 0 0 1 0 1 0。总的编码现在是:
1 | |
此外,对于默认值,统一使用0来占位。因此如果一个field是默认值,它在后续不会有填充数据,但是在struct pointer这里依旧需要0值来占据。again,(据开发组所说)通过压缩算法这些默认值的空间也是可以被压缩掉的。
Data编码
之后写入Book的data信息,struct的data信息分为两部分:定长的data段,和变长的pointer段。
data段的数据只有pageCount,小端形式表示1440:160 5 0 0。因为没有更多data数据了,因此剩下的4个bit补0,得到160 5 0 0 0 0 0 0。总的编码现在是:
1 | |
接下来是pointer段的数据,每个pointer段里的内容都是一个pointer,一般分为list pointer和struct pointer。struct pointer上边已经提到过了,这里title是以list pointer的形式出现,也用一个word标识
1 | |
- A:2 bits,固定是1,代表是list pointer
- B:30 bits,偏移量,用于表示属于这个pointer的数据离本段pointer结束还有几个word。本例中因为
title之后就紧跟字符串的数据了,因此是0 - C:3 bits:用来标识每个元素的大小。这里因为是char所以为2
0 = 0 (e.g. List(Void))
1 = 1 bit
2 = 1 byte
3 = 2 bytes
4 = 4 bytes
5 = 8 bytes (non-pointer)
6 = 8 bytes (pointer)
7 = composite
- D:29 bits:用来标识长度
因此最后的二进制表示为:00000000 00000000 00000000 00000001 00000000 00000000 00000000 01110010,用小端表示为00000001 00000000 00000000 00000000 01110010 00000000 00000000 00000000,用bytes标识为1 0 0 0 114 0 0 0。总的编码现在是:
1 | |
最后把”War and Peace”的ASCII编码按照8位补齐是87 97 114 32 97 110 100 32 80 101 97 99 101 0 0 0,附在数据的最后,总的编码现在是:
1 | |
最后segment的长度5个word也和header里对上了。
优缺点
优点:
首先我们要注意到,对于cap’n proto,所有的数据都是小端存储的(因为没做转换)。在端到端上如果两边都是小端存储(一般情况都是这样),那实际上中途转一次网络序其实意义不大。在这点上节省了绝大部分数据的重新编码。
既然数据是以编码好的形式存储在msg里的,每次对于msg的修改都相当于对编码后的数据修改。因此在传输的时候无需对数据做进一步编码。
收到了二进制数据之后也可以直接附加在一个空的msg上直接使用,这就是无反序列化开销的由来。也无需对数据一段段拷贝。
但是我们需要注意到的是,反序列化无开销并不代表使用过程无开销。通过查看message的接口可以发现,每次对于field的读写实际上都要进行偏移量读写和转换。
此外这一切如果发生在大小端不一致的机器上,或者位宽不一致的机器上都会发生问题,需要额外再转一次,效率自然也会低一些。
缺点:
首先,对于数据的每次修改都需要重新编码,因此序列化开销的代价是每次修改数据都要做一次序列化。同时,每次读取也相当于要做一次反序列化。
其次,关键的一点在于,为了避免修改已有数据,每次修改pointer类型的数据时,都只能在segment的末尾append数据。例如对于title多调用几次set就会让整个segment的大小爆炸增长(https://github.com/capnproto/pycapnp/issues/18)。
解决方式是调用packedEncode,但是packedEncode又会带来编码开销。(至少需要重新进行内存拷贝)。
结论
capnproto不适合业务中频繁修改的情况,尤其是针对一个filed反复修改的情况,会导致附带了很多无关数据。(想象一下有多少c++项目直接拿protobuf message作为业务数据结构使用的)
因此合适的方式是作为传输层的协议,如果你的业务是 业务数据->protobuf->数据流->protobuf->业务数据,那换成cap’n proto从理论上来看至少减少了内存拷贝次数,但是业务数据结构和capnproto数据之间的转换开销也需要进一步profile才好。